
How to Scrape Data from Website
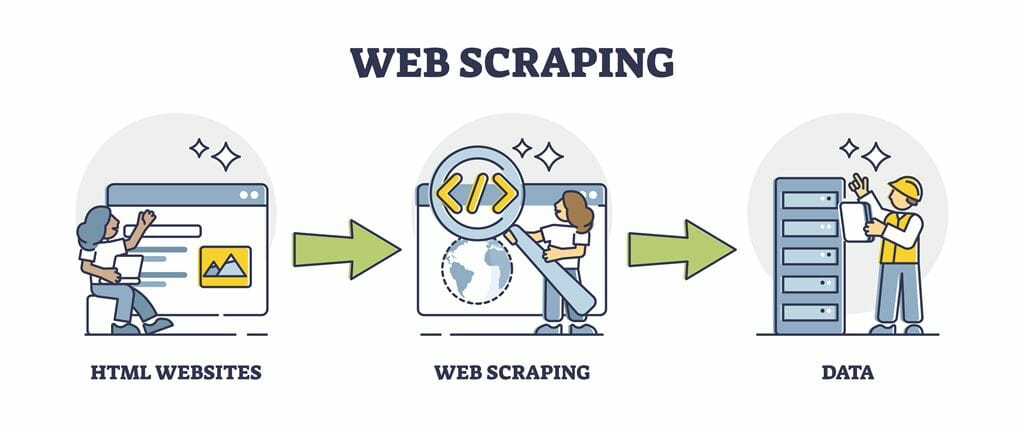
Web scraping is the process of extracting information and data from websites. It involves using automated scripts or tools to retrieve content from web pages, which can then be analyzed, stored, or manipulated for various purposes. Web scraping enables you to gather large amounts of data quickly, which can be immensely useful for research, analysis, data-driven decision-making, and more.
The usefulness of web scraping extends to various fields, including business, research, and data analysis. For instance, companies can use web scraping to monitor competitor prices, gather customer reviews, and track market trends. Researchers can collect data for academic studies, and journalists can extract information for investigative reporting. Web scraping allows you to access valuable data that might not be easily available through other means.
However, web scraping comes with legal and ethical considerations. While scraping public information from websites is generally acceptable, scraping sensitive or private data without permission is unethical and possibly illegal. It’s crucial to understand and respect a website’s terms of use, privacy policies, and any restrictions mentioned in the robots.txt file. Always ensure that your scraping activities are conducted in an ethical and responsible manner.
Getting Started with Web Scraping

Choosing a Programming Language
One of the first and most important decisions you’ll need to make is selecting a programming language. The choice of programming language will significantly influence your experience, efficiency, and the tools available for web scraping. Among the various options, Python stands out as a popular and versatile choice, especially for beginners.
Python for Web Scraping
Python is widely recognized for its simplicity, readability, and extensive collection of libraries designed to facilitate web scraping. Here’s why Python is a fantastic choice for beginners and experienced programmers alike:
- Beautiful Soup: A renowned library for parsing HTML and XML documents. It allows you to navigate the HTML tree, search for specific elements, and extract data effortlessly.
- Requests: This library enables you to send HTTP requests to web servers and retrieve web page content. It’s an essential tool for fetching the HTML you’ll later parse with Beautiful Soup.
Other Language Options
While Python is the recommended language for beginners due to its ease of use and strong scraping libraries, other languages can also be used for web scraping:
- JavaScript: JavaScript is a programming language often associated with web development. It’s particularly useful for scraping websites that rely heavily on client-side rendering and dynamic content. Tools like Puppeteer provide headless browser automation for scraping JavaScript-driven sites.
- Ruby: Ruby is known for its elegant syntax and is another option for web scraping. The Nokogiri library is often used for parsing HTML and XML, similar to Beautiful Soup for Python.
- R: R is a programming language widely used in statistics and data analysis. While it might not be as commonly used for web scraping, it’s capable of extracting data from websites using packages like rest.
Required Tools and Libraries
You’ll need a set of essential tools and libraries that will simplify the process, enhance your productivity, and enable you to effectively extract data from websites. These tools and libraries are crucial for different stages of the web scraping workflow.
Beautiful Soup
Beautiful Soup is a Python library that serves as a powerful ally for parsing HTML and XML documents. It provides an intuitive and user-friendly interface, making it easier to navigate the complex structure of web pages and extract the desired data.
Using Beautiful Soup, you can:
- Parse HTML content: Beautiful Soup can parse HTML strings or files, converting them into a parse tree for manipulation.
- Navigate the parse tree: You can traverse the HTML structure, accessing specific elements, attributes, and content.
- Search for elements: Beautiful Soup allows you to search for elements based on tags, classes, IDs, attributes, and more.
- Extract data: Once you locate elements, you can extract text, attributes, and other information.
Using Requests Library
The Requests library is essential for making HTTP requests to web servers and retrieving the HTML content of web pages. With this library, you can simulate a web browser’s interaction with a website, enabling you to access the data you want to scrape.
Key features of the Requests library include:
- Sending GET and POST requests: You can use Requests to send various types of HTTP requests to retrieve web page content.
- Handling responses: Requests allow you to handle responses from the server, including status codes and headers.
- Session management: The library provides tools for maintaining sessions and handling cookies, which can be essential for maintaining state across requests.
Exploring Scrapy Framework
For more complex web scraping projects and larger-scale data extraction, the Scrapy framework is a robust solution. Scrapy is a powerful and efficient framework designed specifically for web scraping and crawling tasks. It offers a comprehensive set of features, making it a popular choice for advanced scraping projects.
Key features of the Scrapy framework include:
- Asynchronous scraping: Scrapy uses asynchronous programming to handle multiple requests simultaneously, improving scraping speed.
- Spider framework: Scrapy’s spider framework allows you to define how to navigate and extract data from websites.
- Middleware support: You can customize and enhance the scraping process using middleware components for tasks like user agent rotation and IP rotation.
- Pipelines: Scrapy provides pipelines for processing scraped data before storage, allowing you to clean, validate, and transform data.
Understanding HTML and CSS
Basics of HTML

HTML (Hypertext Markup Language) is the standard language used to create web pages. It consists of elements, tags, attributes, and content. Elements define the structure of a webpage, and they are enclosed in tags. Attributes provide additional information about an element, while the content is the actual text or media displayed on the page.
Elements like headings, paragraphs, tables, and lists contain the data you might want to extract. By inspecting the HTML source code of a webpage, you can identify the elements you need to target for scraping.
CSS

CSS (Cascading Style Sheets) is used to style and format web pages, controlling the layout, colours, fonts, and more. CSS selectors are used to target specific HTML elements for styling. In web scraping, CSS selectors play a vital role in pinpointing the data you want to extract.
By familiarizing yourself with CSS selectors, you can effectively locate the content you’re interested in. Elements can be selected by their tag names, classes, IDs, attributes, and even their relationships to other elements.
Navigating and Extracting Data
Inspecting the Web Page
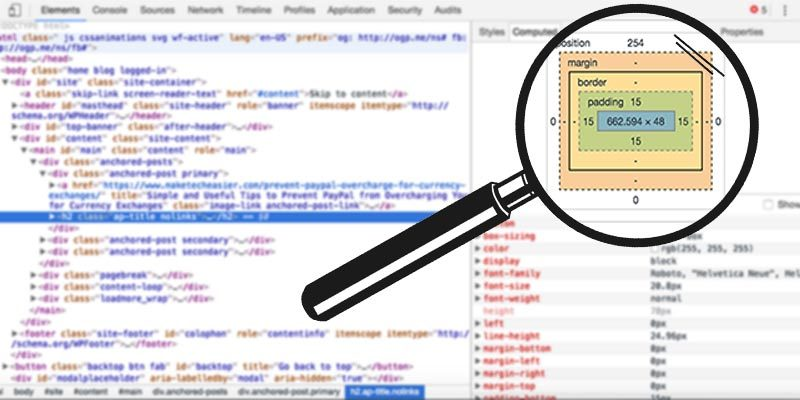
Before you can start scraping, you need to inspect the structure of the web page using browser developer tools. Most modern browsers allow you to right-click on an element and select “Inspect” to open the developer tools. This reveals the HTML source code and provides insights into the structure of the page.
Using Beautiful Soup
Beautiful Soup simplifies the process of parsing and navigating HTML documents. To begin, you’ll need to install Beautiful Soup and Requests. Once installed, you can use Requests to fetch the HTML content of a web page and Beautiful Soup to parse and navigate the HTML.
You can search for elements using various methods, such as finding by tag name, class, or ID. Beautiful Soup allows you to traverse the HTML tree, access attributes, and extract data with ease.
Making HTTP Requests
To access web pages and retrieve their content, you need to make HTTP requests. The Requests library in Python enables you to send GET and POST requests. GET requests retrieve data from a server, while POST requests send data to a server for processing.
When making requests, you’ll also encounter different HTTP status codes, which indicate the outcome of the request. Understanding these status codes helps you handle responses effectively and troubleshoot any issues.
Working with Dynamic Websites
Not all websites load their content statically. Some websites use AJAX (Asynchronous JavaScript and XML) to load data dynamically, which can complicate the scraping process. Additionally, JavaScript-driven interactions might require you to simulate user behaviour to access certain content.
To scrape dynamic websites, you might need to use tools like headless browsers or APIs that provide the data in a structured format. Selenium is a popular tool for automated browser interaction, allowing you to execute JavaScript, interact with dynamic elements, and retrieve the rendered content.
Data Parsing and Storage
Cleaning and Processing Scraped Data
Once you’ve extracted data from web pages, it’s essential to clean and process the scraped information. The extracted data may include HTML tags, unwanted characters, or formatting artifacts that need to be removed for analysis.
Regular expressions and string manipulation can help clean up the data. Additionally, you might want to convert extracted data into usable formats, such as dates, numbers, or structured objects.
Storing Data
After cleaning the data, you can store it for further analysis or use. Common storage options include saving data to CSV (Comma-Separated Values) files, JSON (JavaScript Object Notation) files, or databases like SQLite or MySQL.
Choosing the appropriate storage format depends on the nature of your data and your intended use. CSV is suitable for tabular data, while JSON is more flexible for structured information. Databases provide powerful querying capabilities and can handle larger datasets.
Best Practices and Challenges
Ethical Considerations
When scraping websites, it’s crucial to consider the ethical aspects of your actions. Always check a website’s robots.txt file, which provides guidelines on whether scraping is allowed and which parts of the site are off-limits. Respect a website’s terms of use and privacy policies, and avoid overloading its servers with excessive requests.
Additionally, be mindful of the data you’re scraping. Avoid collecting sensitive or personal information without permission, and ensure that your scraping activities do not violate any laws or regulations.
Handling Common Challenges
Web scraping can present various challenges, including anti-scraping mechanisms implemented by websites to prevent automated access. To bypass these mechanisms, you might need to rotate IP addresses, use user agents, or employ CAPTCHA-solving services.
Pagination and infinite scrolling are common techniques used by websites to display large amounts of data. Scraping such content requires simulating user interactions and extracting data from multiple pages.
Performance and Efficiency
Efficiency is crucial when scraping websites to avoid overloading servers and causing disruptions. To optimize scraping speed, use asynchronous programming techniques to make multiple requests simultaneously. Implement rate limiting and introduce delays between requests to be considerate of the target website’s resources.
Minimizing the impact on target websites also involves caching data locally, avoiding redundant requests, and handling errors gracefully to ensure smooth scraping operations.
Conclusion

In this beginner’s guide to web scraping, you’ve gained a solid foundation in the art of extracting valuable data from websites. Armed with the knowledge of selecting the appropriate programming language, understanding HTML and CSS structures, navigating web pages with finesse, and tackling common challenges head-on, you are now equipped to embark on your exciting web scraping journey. Always keep ethical considerations at the forefront of your efforts, ensuring that your scraping activities adhere to responsible and respectful data extraction practices.
Consider leveraging the expertise of Ubique Digital Solutions to supercharge your business endeavours. With a wealth of experience and a proven track record in harnessing data-driven insights, we can help you unlock new opportunities, optimize your strategies, and propel your business toward resounding success. Let us guide you on a transformative journey to achieve your business goals. Reach out to us today.
FAQs
Q: Is web scraping legal?
Web scraping is generally legal when done responsibly and in compliance with a website’s terms of use and applicable laws. However, scraping sensitive or private data without permission can be illegal and unethical.
Q: What are some real-world applications of web scraping?
Web scraping has numerous applications, including price monitoring, market research, sentiment analysis, news aggregation, job searching, and academic research.
Q: Can I scrape any website I want?
While many websites can be scraped, it’s important to respect a website’s guidelines, terms of use, and robots.txt file. Avoid scraping sites that explicitly prohibit it or impose restrictions.
Q: How often should I scrape a website to avoid overloading their server?
Implement rate limiting and considerate delay intervals between requests to avoid overwhelming a website’s server. The appropriate scraping frequency depends on the target site’s capacity and guidelines.
Q: What is the difference between web scraping and web crawling?
Web scraping focuses on extracting specific data from web pages, while web crawling involves systematically browsing and indexing the entire web to gather information.
Q: Do I need to have programming experience to start web scraping?
While programming experience is beneficial, you can start web scraping with basic knowledge and gradually learn more advanced techniques as you progress.
")

")


